現在地
土木工学におけるAI応用チュートリアル(8)
対話システムと文章生成(阿部,杉崎)
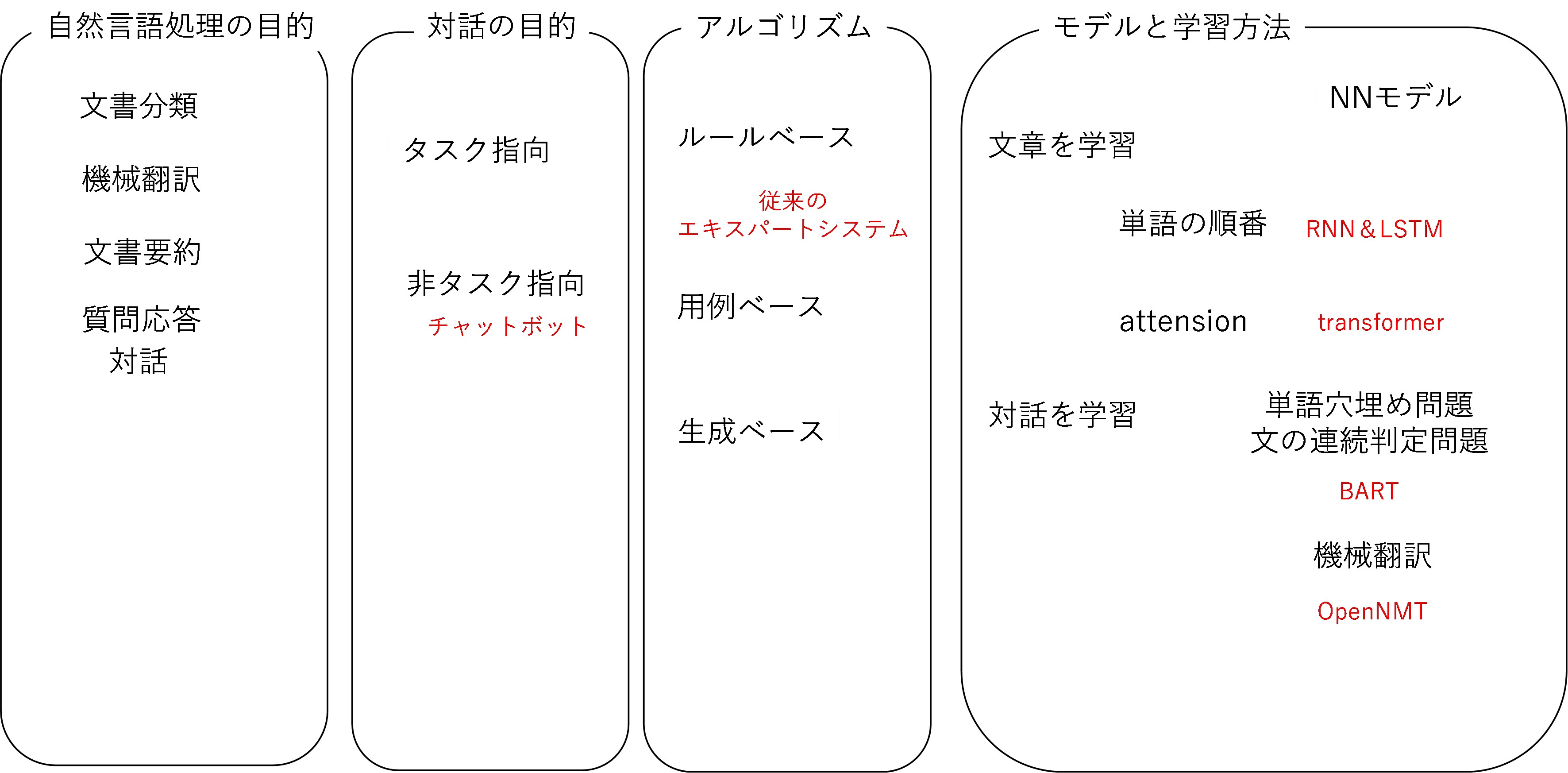
〇自然言語処理の目的
自然言語処理の目的としては,機械翻訳,文書要約,文書分類,対話(質問応答)などがあります.近年ブームになっている深層学習では,入力と出力のデータがたくさん必要となりますが,機械翻訳を考えれば,ある言語を別の言語で言い替えた入力と出力データの対が多くできることがわかると思います.それに対して,文書要約などでは,ある文書を要約したデータというのはそれほど多くないと思われますので,深層学習を利用するためには一工夫必要となるでしょう.次に,対話システムについて考えると,近年はSNSやツイッターなど,誰かのつぶやきに対する応答データが多くあることがわかります.このようなつぶやきと回答のペアデータを利用した対話モデルなどが深層学習を利用して開発され,それらはアップルのSiriやグーグルやアマゾンなどのスピーカー機能などとして実用化されています.
〇対話システムの目的は
それでは,グーグルやアマゾンなどの対話システムをそのまま専門的な知識を得るための対話システムとして利用することができるでしょうか?
まず,みなさんはどのような質問をスピーカーにしているでしょうか?例えば,天気を聞くというようなことがあるかと思います.このような天気を知りたいなどの明確な目的がある対話システムはタスク指向対話システムと呼ばれています.天気を知りたいだけであれば,深層学習などを利用しなくても,天気を知りたい場所や時間などの特定の条件を入力して,天気予報などの情報を検索して回答することができると考えられますが,このような特定のルールに対して回答を作るルールベース方式の対話システムが検討されてきました.しかし,対話は天気の質問だけとは限りません,色々な質問に対して,何か答えを作る対話システムは,非タスク指向対話システムと言われますが,これはいわゆるチャットボットと呼ばれているものです.このような特定なタスクを伴わない対話にも,人間にとっての癒しなどの効果があると考えられ多く検討されています.
また,対話を実現する際に,なんでもかんでも答えるような対話システムを作るためには,特定のドメインに特化しないデータ(open domain)を学習する必要がありますが,特定の対話にだけ答えるようなFAQシステムなどでは,適用分野と用途を絞り込んだ対話システムとして,絞り込んだ専門分野や,ある特定の領域のデータ(Closed domain)の学習を行うような対話システムが考えられます.
土木の分野で期待されている対話システムというものはどのようなものでしょうか.
〇土木に必要な対話システムとは
我々は専門的な情報を得るためには,各種の基準を参照することをします.専門的な知識を持っているということは,必要な情報がどこに書いてあるかを探せる能力であるともいえます.しかし,近年では,必要な情報は多く散在し,また個人や組織のやるべきタスクは特定されず,様々なものをこなす必要があります.このため,いわゆるエキスパートシステムのような対話システムが期待されています.用途を絞ることで,より専門的な対話を実現しようとするものがエキスパートシステムと言えますが,従来のエキスパートシステムはルールベースのものであり,基本的に予め用意した対話のシナリオ(スクリプト)等を利用して動作するものです.近年の深層学習の進展を考えれば,用例ベースや生成ベースの対話システムを考えてみることがよいと思われます.また土木の業務の遂行においては,技術的な知識だけではなく,受発注を効率化するための情報や,部外協議などの業務を円滑に進めるような知識も重要となります.また,施工や品質の管理などでは,必要な情報をあるべきところに入れておき,必要になったら取り出すような仕組みが重要となると考えられます.これらのエビデンスベースの情報管理においても,チャットボットのような仕組みは重要となると考えられます.
〇対話システムにおけるモデルと学習方法
言葉を理解するとはどのようなことでしょうか?深層学習を利用しない手法では,例えば,品詞,単語分割,語義曖昧性解消,固有表現抽出,構文解析,述語項構造認識などの手順をモデル化する手法が検討されてきました.このような自然言語処理の手法はかなり敷居の高い分析だったと言えるでしょう.それに対して,深層学習では,入出力データをニューラルネットワークでつなげればよいと考えることができます.
さてニューラルネットワークはどのように賢くなっていくのでしょうか.ニューラルモデルを利用した自然言語処理手法をして,BERT(Bidirectional Encoder Representations from Transformers)というのがあります.BERTでできることは,文章の感情分類,質問応答,文章から人名,組織名,地名などを抽出する固有表現抽出など様々ですが,教師なしデータで事前学習を行うのが特徴となっています.事前学習では,単語穴埋め問題と文の連続判定問題というのを行っています.文章に対して,ランダムに穴埋め問題を作って,入力と出力(答え)を学習していくことでニューラルネットワークを賢くしていきます.また,実際に連続した文,実際には連続していない二つの文を用意して,それらを学習して正答率を上げていくことで,あたかもAIが文脈を理解しているかのように賢くなっていきます.このような事前学習をしたモデルを目的に応じてファインチューニングすることで対話を実現します.
次に,ニューラルネットワークの構造について考えてみましょう.文章は単語のつながりが重要になることは明白です.また,単語の共起というものが大事になります.同じ文脈で出てくる単語は関連があると言え,これらは関連がある単語としてベクトル化されます.入力と出力を繋ぐ際に単語の順番を考慮するためのモデルはRNNと言われ,時系列的な依存関係を隠れ層に持ったニューラルネットワークですが,このようなニューラルネットワークを上手に学習することができるようになり,機械翻訳の精度が上がったことが知られています.さらに長期的な記憶のような機構を入れるためにLSTMといったモデルが提案されています.「Attention Is All You Need(Transformer)」という論文以降は,attention機構「入力されたベクトルによって重みを計算し,その重みに基づいて索引ベクトルから任意のベクトルを出力するモデル」を利用した手法が構築され,Transformerモデルとして開発され,さらに効率よく学習するReformerモデルなどが開発され精度が向上しています.
〇点検基準を学習して言語生成してみよう
対話システムを構築する際には,どのようなデータを利用して学習をすることができるでしょうか.ツイッターのようなつぶやきと回答のような対話データが多く得られるのであれば,対話の対関係を利用したモデルを構築するのがよいでしょう.このような問題では,OpenNMTなどの機械翻訳などのモデルが利用できます.土木の問題に対するQ&Aなどが多く得られるのであれば,このようなモデルを検討して対話システムを作ることもできるでしょう.
それに対して,点検基準などのテキストデータは,小説などと同様の文章であり,この場合は,ある単語に対して近くによくでる単語,といった関係を利用したモデルにより生成を行うことになります.ある単語の次にどのような単語が来るかを予測する方法として,マルコフ過程を利用したマルコフ連鎖を利用したものなどが開発されてきましたが,近年では,ニューラルネットワークを利用したRNNモデルやLSTMモデルがあります.ここでは,LSTMモデルを利用した生成モデルを示します.
LSTMモデルでは,文字のつながりを予測する場合と,単語のつながりを予測する方法が考えられます.例えば以下のようなものが考えられます.
・文字の予測
8文字単位(maxlen=8)で次の1文字を予測し,それを1文字(step=1)づつずらしながらデータセットを作る.つまり,入力8文字,出力1文字.
・単語の予測
文章を分かち書きにより単語に分け,単語のつながりを学習する.例えば,5つの単語(maxlen=5)から次の単語を予測するなど.
これらの予測結果は,スタートする単語によってその先の生成結果が相違しますが,学習ができているかを確認する上では,学習の進捗に対して,同じ単語でスタートして,生成結果が妥当になっているかを確認することが行われます.実際にプログラムを動作させることで,学習されていくことが確認できますが,まだまだ生成結果を実務で利用するレベルにはなっていないと考えられます.
〇よりよい言語生成結果を求めて
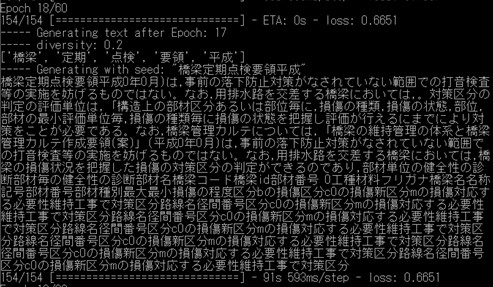
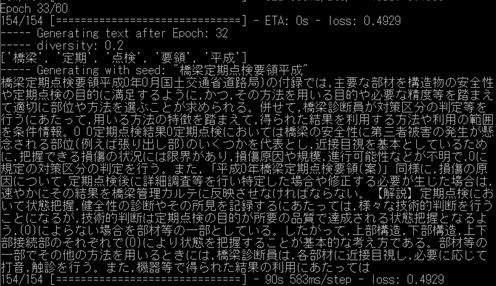
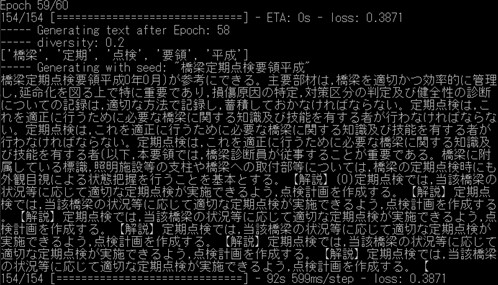
よりよい言語生成結果にするためにできることを考えてみましょう.今すぐにでもできることはいくつかあります.まずは,学習する言語データを増やすのはどうでしょうか.例えば,定期点検マニュアルだけでなく,補修補強について書かれた言語データも学習すればより多様な結果が出るかと思います.他にも,学習する必要のない単語は前処理して置換してしまうことがあります.さらに重要なこととして,土木の用語を網羅した辞書を作るというのがあります.日本語の分析においては,単語の切れ目を見つける分かち書きということが行われますが,例えば「防護柵」などの単語は,通常は「防護」と「柵」が別々の単語と認識されますが,「防護柵」という単語を登録しておけば一つの単語として処理することができます.以上のことを行って,モデルを学習してみた結果を以下に示します.
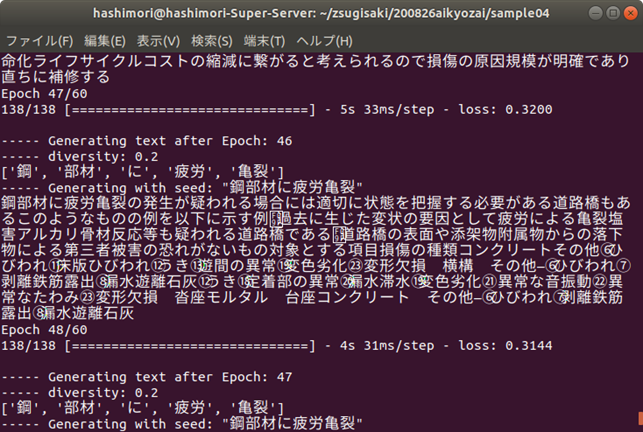
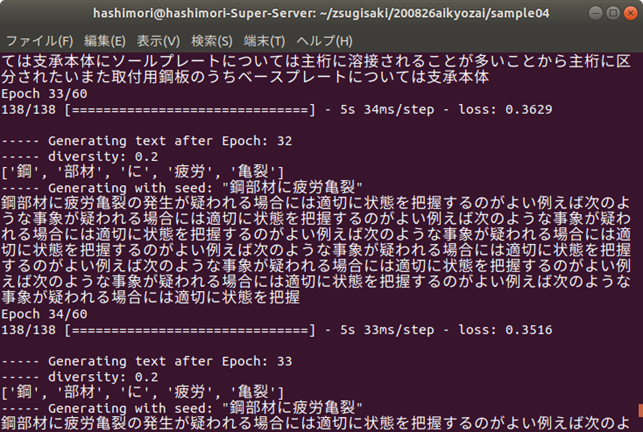
今回は,「鋼部材に疲労亀裂」の後の単語を生成してみましょう.エポックが小さい(学習が進んでいない)段階では同じ単語を羅列するような結果になっています.学習が進んでいくと,読んでも違和感のない文章が生成されるようになりますが,主に,「点検ルールに関する記述」,「詳細点検に言及したもの」,「損傷に対する措置や記録の方法」など,様々な観点から単語を生成していくことがわかります.ただし,鋼材の疲労亀裂という損傷の内容から,明らかにコンクリートの損傷の内容になってしまうものなども見られますので,まだまだ改善の余地はありそうです.
さらに,よりよい生成モデルの構築のためには,近年精度の向上が著しいアテンション機構を利用したモデルを試してみることや,また,単語を予測するモデルでは,専門用語などの辞書を整備することで分かち書きの精度を上げることでよりよいモデルとなることが想定されます.また画像などの情報と合わせた生成モデルが期待されています.手法の理解を進めるとともに,業務改善に向けたユースケースを作っていけるかが鍵となるでしょう.
・学習が進んでいない段階


・点検ルールに関する記述
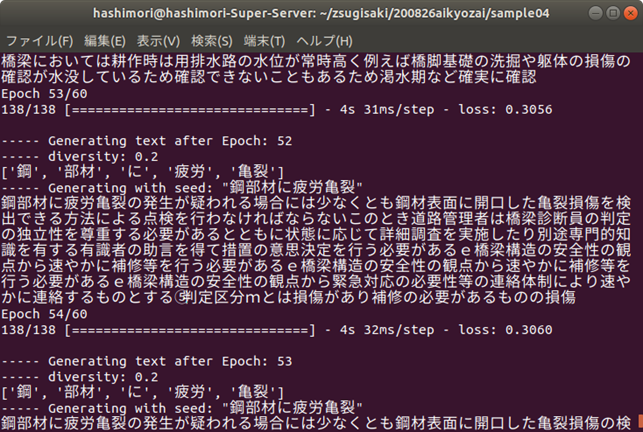
・詳細点検方法に関する記述
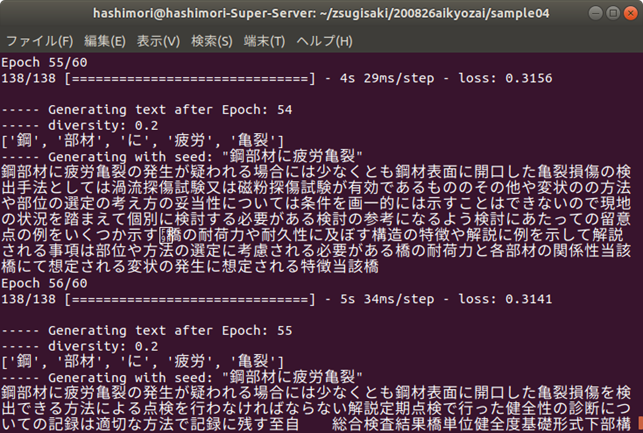
・措置や記録に関する記述
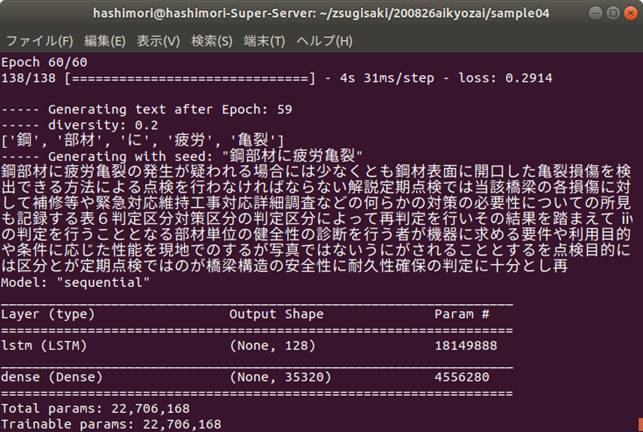
・コンクリートの記述に移行
| 添付 | サイズ |
|---|---|
| 3.79 KB | |
| 4.03 KB | |
| 94.43 KB | |
| 391 KB | |
| 71.1 KB | |
| 71.59 KB | |
| 72.21 KB | |
| 393.43 KB | |
| 403.46 KB | |
| 382.88 KB | |
| 362.88 KB | |
| 409.08 KB | |
| 400.32 KB | |
| 329.22 KB |
{kind=link}