現在地
土木工学におけるAI応用チュートリアル(6)
事例でAIのできることを知ろう
その3 自然言語処理学習例(阿部雅人,杉崎光一)
〇自然言語処理
自然言語処理AIのキラーコンテンツとしては自動翻訳がありますが,問い合わせ対応を支援するチャットボットや,事務作業支援のためのRPA(ロボティック・プロセス・オートメーション)などすでに実用化されているものが多くあります.具体的な手法としては,twitterなどSNSのデータを利用して文章中で出現頻度が高い単語を複数選び,その頻度に応じた大きさで図示するWord Cloudと言われる手法や,言葉のつながりや意味を解釈するためのword2vecなどの手法などがあり,広告業界などでマーケティング手法として活用されております.インフラメンテナンスにおいても,過去の点検記録などを自然言語処理して,対策方法などがレコメンドされる機能などが期待されます.
〇実装事例 示方書や点検マニュアルの解析 (サンプルプログラム)
橋梁点検マニュアルに記載されているテキスト情報について,Word Cloudを実装して,米国の点検マニュアルと日本の定期点検要領を比較してみましょう.図は適用した結果です.米国のマニュアルのほうが,橋自体に対する単語(bridge,structure,deck,culvertなど)が多いように思われます.それに対して,日本の点検要領は,橋自体に対する説明は多くなく,ひび割れ,腐食といった損傷に関する単語や,診断,措置,記録などのプロセスに関する言葉が相対的に多いことがわかりますね.この要因として推察されることですが,日本の点検要領は基準であるのに対し,米国のマニュアルでは教材的な要素が強いなどが挙げられるでしょう.
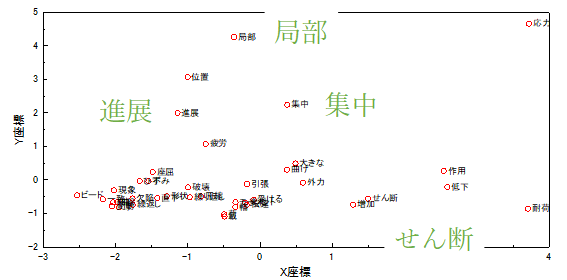
次に日本の点検基準や補修補強の手引きなどのテキストを,言葉のつながりや意味を解釈するためのword2vecを利用して分析してみましょう.word2vecは仮説として,単語の意味は周辺に現れる単語の頻度で表現できるというものです.例えば,「応力」に関連する単語について関連する単語を抽出して関連性が高いものをマッピングして可視化した結果ですが,応力という言葉には「局部」,「集中」などの言葉が周辺に多くあらわれるため,近くに表示されていることがわかります.また「進展」,「疲労」などの言葉もあります.これらの単語は足し合わせなどをすることもでき,「応力」+「溶接」などを足し合わせると「集中」などの言葉が大きく関連していることが確率値として出てきます.この結果は,補修補強などの文章において,これらの言葉の頻出頻度が類似しており,また時系列的に順番で出てくるなどがわかりますので,原因や処方箋などを書く際の参考になるかもしれません.
Word Cloud(米国)

Word Cloud(日本)

単語の関係
単語の関連度

※サンプルプログラム
〇概要
・点検マニュアルなどのテキストデータを分かち書きして,単語の頻度を分析して単語の関係を可視化するプログラム
・mecab,BeautifulSoup,gensim(word2vec),wordcloudなどを利用
・点検マニュアルなどのテキスト化したデータ(textdataフォルダ)
https://committees.jsce.or.jp/struct10/system/files/textdata.zip
〇ファイル名
・sampleprog_3_1_wordcloud.py
テキストデータを分かち書きして保存する.分かち書きしたデータをwordcloudを利用して可視化する.日本と米国のデータで可視化結果を比較
https://committees.jsce.or.jp/struct10/system/files/sampleprog_3_1_wordc...
・sampleprog_3_2_word2vecmodel.py
分かち書きしたデータを読み込み,word2vecのモデルを作成する.
https://committees.jsce.or.jp/struct10/system/files/sampleprog_3_2_word2...
・sampleprog_3_3_word2vecapply.py
作成したモデルを利用して,単語の関係を可視化する.
https://committees.jsce.or.jp/struct10/system/files/sampleprog_3_3_word2...
| 添付 | サイズ |
|---|---|
| 26.43 KB | |
| 65.6 KB | |
| 17.42 KB | |
| 58.49 KB | |
| 3.9 KB | |
| 812 byte | |
| 1.57 KB | |
| 2.33 MB |