現在地
土木工学におけるAI応用チュートリアル(2)
橋梁形式分類AIを実装してみよう (阿部雅人,杉崎光一)
その1 犬猫分類問題でAIを理解する
a) AIによる画像認識で犬猫を分類する
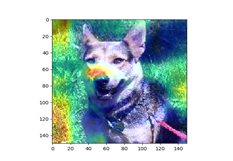
AIにおける深層学習を利用した画像認識として,以下に説明する犬と猫を分類する事例があり,これらを理解することで,AI手法の中で特に深層学習の理解を深めることができます.犬猫の分類は,インターネットなどにデータがあり,実装できるプログラムを含めて,既存の手法が豊富にネット上にあります.また,学習プログラムだけでなく、AIが何を着目しているか分類するプログラムなどもネット上のものを活用できます.例えば,Grad-camという手法を利用すれば,犬と猫を鼻の特徴に着目して分類していることがわかります.
| 猫 | 犬 |
 |
 |
b) AIを学習してモデルを評価するとは
〇AIの学習の仕方
AIがデータから学習する方法は,一般的に以下の3種類があると言われています.犬猫分類の問題は一番実装が容易な教師あり学習を利用します.教師ありですので,画像には犬なのか猫なのかあらかじめ答えを用意する(アノテーション)必要があります.
A.教師あり学習
犬猫の画像があり,犬と猫を分けるラベルが付いていて,それを分類する問題です.
⇒分類されたデータに境界線を引き,未知のデータを分類
B.教師なし学習
犬猫の画像をもっているが,犬猫のラベルはついておらず,クラスタリングなどで分類する問題です.
⇒特徴量をデータから抽出して,クラスタリングにより分類(異常データを分類できるかなどでも活用)
C.半教師あり学習
犬の画像しかなく,犬を表すモデルを学習して,猫画像が新規に来た時に犬と違うと分類する問題です.
⇒正常データの特徴量を抽出して,未知の異常を検出問題など
〇AIを評価しよう
学習したAIは評価しなくてはいけません.その際に学習したデータ(trainデータ)で評価するのではなく,検証用(validationデータ)のデータを用意しましょう.検証用のデータをモデルに入力して正解である率が高ければ(正解率)よい学習が行えたモデルと言えます.これらの作業は,交差検証とよばれます.教師データでは正解率が高いが,検証用データで正解率が低くなる問題を過学習と呼びます.検証用データで正解率が高いモデルは汎化性能が高いモデルと呼ばれます.
〇AIと特徴量
AIは画像の何を根拠に犬と猫を分類するのでしょうか.よく言われる問題として,AI,特に深層学習はブラックボックスであると言われます.画像はピクセルごとに輝度のデータが入ったものですので,輝度のデータの特徴を利用して分類しているに違いありません.どのような輝度の特徴を利用して分類しているかがわかる,つまり,犬の特徴や猫の特徴などをちゃんととらえていることがわかれば,AIを利用する我々も安心してAIの答えを信頼することができます.これらの手法は,説明可能AI(XAI:Explainable AI)と呼ばれて,様々な方法が研究開発されています.
〇学習環境の構築と実装環境
AIはニューラルネットワークというアルゴリズムを多く利用しています.この計算は複数の入力をニューロン(ノード)が受け取り,それぞれに重みを付けて統合して,活性化関数を通してある値より大きなものを次のノードに送っていく,それを繰り返して最終的な出力を出す計算です.計算された出力と正解を比較してその誤差を小さくする(バックプロパゲーション)ことで重みを最適にする計算を繰り返します.
近年流行している深層学習はこのノードの数や層が深くなったものですので,一つ一つは単純な計算ですが,多数の計算を行います.そのためCPUを利用した計算よりもGPUを利用した計算の方が早く実行できることが知られています.GPUは一般的なPCには実装されていませんので,深層学習を行うためにスタンドアロンPCでGPUパソコンを用意するか,もしくは,クラウド環境でGPUを利用することが行われています.
スタンドアロンで環境を用意する場合は,Pythonなどのコードを実行するためのソフト的な環境(アナコンダなどが有名)を構築する必要があることにも注意が必要です.クラウドを利用する場合はソフト的な環境も用意されていることが一般的ですので,ちょっと試してみたいなどではよいかもしれません.
pythonなどでAIプログラムを構築する際には,機械学習を効率よく実装できるフレームワークが開発されています.深層学習などを利用する代表的なものとしては,TensorFlowやPyTorchなどがあります.さらに,Tensorflowをベースにしてさらに利用しやすくしたKerasなどのラッパーと呼ばれるものが用意されています.プログラムの柔軟性と利用しやすさはトレードオフですので,問題の難易度に応じて選択してください.
〇既存のデータとモデルを活用しよう
AIは一から自分ですべて作るのは大変です.特に深層学習のデータやモデルはインターネットにある既存のものを活用することが近道です.よく利用されているものとして, GitHubという開発プラットフォームがあり,オープンソースとしてデータがリポジトリにアップロードされています.例えば下記のようなものが参考になるでしょう.利用されているプログラムやデータがダウンロード(クローンやフォーク)でき,それらの利用方法も記載されています.また,SNS機能があり,質問や回答をやりとりすることができ,まさに開発技術者のプラットフォームと言えるでしょう.
https://github.com/crotsu/Bousai_AI
https://github.com/sekilab/RoadDamageDetector

c) 犬猫分類問題を実装する
〇画像データ収集
インターネットなどを利用してデータを収集します. ネットから画像収集するクローリング技術と呼ばれる方法を利用することもできます.ただし画像を利用する際には著作権などに気を付けてください.点検データなどでは,橋梁名を抜くなどのデータの匿名化などによって対応することも考えられます.
〇画像の前処理
教師データは多ければ多いほど良いですが,画像を収集するのには労力が必要です.このため教師データの画像枚数を増やす方法として,画像を引き延ばしたり,回転させたりするデータ拡張技術があります.加工した画像に対しても答えは同じですが,加工されることで人間の目でも画像が変化したことがわかりますので,そのような画像を正確に分類できればAIはより賢くなっていると言えるでしょう.
※画像データは2次元の配列です.モデルに入力する際には配列の構造が重要です.pythonで利用されているnumpyのarrayとpytorchで利用されているtensorなどではこの配列構造が相違します.お互いに変換するプログラムなどが利用できます.AIモデルを作成するパッケージに応じて入力データを変換してください.
〇アノテーション
画像に対して正解を付ける作業です.例えば,犬の画像はdogフォルダに,猫の画像はcatフォルダに分類したり,犬の画像のファイル名にはdogを,猫の画像にはcatなどを付与しておけば,プログラムの中で正解となるベクトル(label)を作ることができます.
〇学習データの作成(既存プログラムの修正)
犬猫分類を実装するプログラムは,kaggleと呼ばれるコンテストなどでも世界的に行われており,そのため様々な開発者が挑戦し,インターネットにファイルがアップロードされています.また,深層学習の教科書にも取り上げられているためgithabと呼ばれるソフトウェア開発のプラットフォームに実装したプログラムや学習用の画像データがアップロードされています.それらをダウンロードして実装する際にはいくつか修正が必要となります.特に利用するデータの保存先や保存方法によってプログラムでデータを読み込む際のパスなどの設定があります.プログラムでデータを学習する際には,データを教師データと検証用データに分ける必要があります.
〇学習方法
学習は,入力データをモデルに入力して出力を算出し,出力と正解との差が小さくなるようにパラメータを変化させる最適化計算を行います.これには勾配法と言われる方法が通常利用されます.勾配法を適用する際には,パラメータを更新するたびにすべてデータで誤差を計算するのは効率が悪いために,バッチサイズと呼ばれる誤算を計算する際の画像の枚数を決め,ランダムに選んで画像の組を作成して計算を行います.そのために,データローダーというものを利用します.バッチサイズは2のn乗の値が使われることが多いですが,画像の枚数に応じて選択してください.データセットの件数が数百件程度であれば32,64で試してみればよいでしょう.学習回数はイテレーションやエポックと呼ばれますが,学習する画像枚数とバッチサイズ数で回数が決まります.例えば1000枚の画像があり,バッチサイズが200であれば,すべての学習データを利用するためには5回学習する必要があるのでイテレーション数は5になります.この学習を何回繰り返すかがエポック数です.
〇学習
モデルを一から作るのではなく,既存の学習済みモデルを利用することでよいAIモデルを作ることができます.その場合は,転移学習やファインチューニングと呼ばれる手法を利用します.エポック数が小さすぎて学習が完了しない場合や,ハイパーパラメーターと呼ばれる学習率などにより答えが変わることがありますので注意が必要です.
〇検証
学習したモデルを評価します.正解率,適合率など複数の指標がありますので注意しましょう.学習結果の可視化はグラフで行う場合などがありますが,どの評価関数を選ぶかなどを決めます.パッケージには可視化するかしないかを変数で決めれば勝手に可視化してくれるものが多いです.
〇モデルを利用する
学習したモデルのパラメータを保存しておくことが可能です.保存したパラメータを再度読み込むこともできます.検証用データは学習ができているかを確認するためのデータですが,それとは別にテスト用のデータを利用する場合もあります.テストデータを実際にモデルに入力して分類結果を確認するなど,モデルを利用してみることでよりプログラムの理解を高めることができます.
※参考 医療における下記のサイト
https://japan-medical-ai.github.io/medical-ai-course-materials/
Google Colaboratoryを利用して,実際にプログラムの実装までできるようになっています.
| 添付 | サイズ |
|---|---|
| 50.99 KB | |
| 58.36 KB | |
| 50.31 KB | |
| 50.73 KB |